
Scraping IMDB data using python(Beautiful soup)

The source website I used here to pull data is IMDB. From top rated movies page.
so here is a screenshot of the data that's available on the web
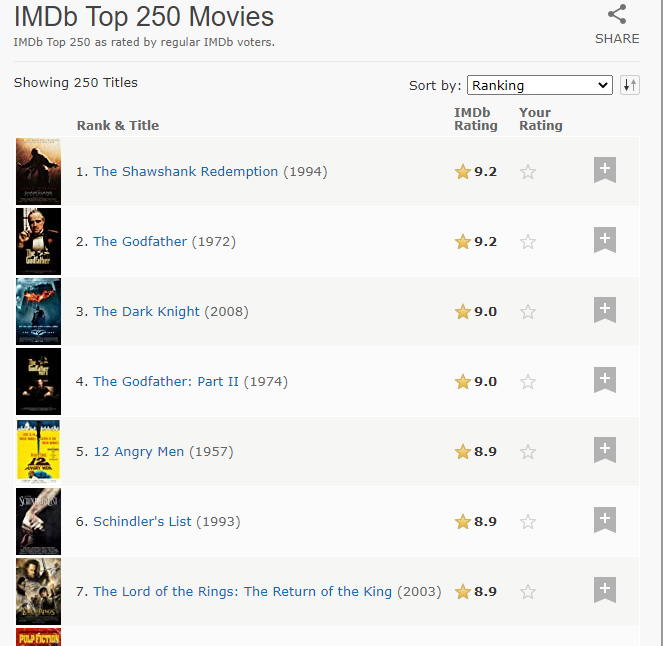
and store it in an excel file like this.
 To scrape the data I used the requests module and beautiful soup python library.
And to save the data in an excel file I used openpyxl
To scrape the data I used the requests module and beautiful soup python library.
And to save the data in an excel file I used openpyxl
Requests module: Requests module helps us to make a request to a web page, and print the response text.
Beautiful Soup: beautiful soup library is used for pulling data out of HTML and XML files.
Installing beautiful soup and openpyxl
-pip3 install bs4
- pip3 install openpyxl
Setting up Excel file using openpyxl to store data later
excel=openpyxl.Workbook()
sheet=excel.active
sheet.title='top rated movies'
Downloading the data from the IMDB
import requests module fetches the source code of the source website using requests and convert the 'source' to HTML text
import requests
source = requests.get('https://www.imdb.com/chart/top/')
source.raise_for_status()
soup=BeautifulSoup(source.text,'html.parser')
Find the target HTML tags for the required data
since the target data is in the table tag and it is in the
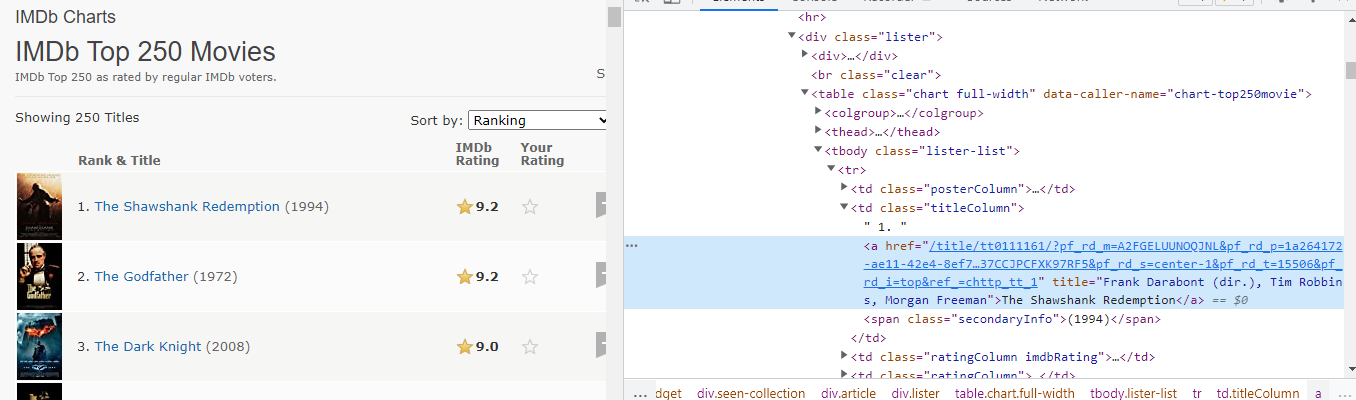
by observing the inspection window, we can clearly see that the title of the movie is enclosed in a 'a' tag.
To fetch all tr tags
movies=soup.find('tbody',class_='lister-list').find_all('tr')
find_all method gives us a list, so now we need to loop through it to fetch the appropriate content.
for movie in movies:
title= movie.find('td',class_='titleColumn').a.text
rank=movie.find('td',class_='titleColumn').get_text(strip=True).split('.')[0]
year=movie.find('td',class_='titleColumn').span.text.strip('()')
rating = movie.find('td',class_='ratingColumn imdbRating').strong.text
sheet.append([rank,title,year,rating])
Save the excel file with the name
excel.save('imdbtoprated.xlsx')
Full source code
from csv import excel
from turtle import title
from bs4 import BeautifulSoup
import requests
import openpyxl
excel=openpyxl.Workbook()
sheet=excel.active
sheet.title='top rated movies'
source = requests.get('https://www.imdb.com/chart/top/')
source.raise_for_status()
soup=BeautifulSoup(source.text,'html.parser')
movies=soup.find('tbody',class_='lister-list').find_all('tr')
for movie in movies:
title= movie.find('td',class_='titleColumn').a.text
rank=movie.find('td',class_='titleColumn').get_text(strip=True).split('.')[0]
year=movie.find('td',class_='titleColumn').span.text.strip('()')
rating = movie.find('td',class_='ratingColumn imdbRating').strong.text
sheet.append([rank,title,year,rating])
excel.save('imdbtoprated.xlsx')
After executing the code, you can see a new excel file created in the current directory.